



Postępy w zautomatyzowanym przetwarzaniu danych i algorytmach uczenia maszynowego zwiększają wartość modeli i symulacji produktów oraz procesów przemysłowych.
Nowoczesne procesy produkcyjne generują wielkie ilości danych. W czasach, gdy liczba czujników zainstalowanych w halach fabrycznych znacznie się zwiększyła wraz z wykorzystywaniem technologii Przemysłowego Internetu Rzeczy (IIoT), liczba dostępnych danych staje się jeszcze większa.
W przeszłości dane były zwykle wykorzystywane w zakładach przemysłowych w konserwatywny sposób – z perspektywy czasu zasadniczo do informowania użytkowników, co dzieje się w hali fabrycznej. Dane te mogły być wykorzystywane to sporządzania raportów wymaganych przepisami oraz, w niektórych przypadkach, do odkrywania trendów i identyfikowania problemów.
Jednak obecnie, gdy technologie sztucznej inteligencji (AI) oraz uczenia maszynowego (ML) zyskały na znaczeniu, możliwości wykorzystywania w praktyce danych generowanych w fabrykach stały się niemal nieograniczone. Najczęściej dane te wykorzystuje się do identyfikowania wzorców, które z kolei są informacjami umożliwiającymi przyśpieszanie wprowadzania produktów na rynek oraz optymalizację procesów produkcji.
Komputery wyposażone w intuicję
Kiedyś specjaliści uważali, że komputery mogą jedynie wykorzystywać algorytmy rozumiane przez człowieka. Zakładali też, że nie ma sposobu, aby nauczyć program komputerowy ćwiczenia intuicji, np. odróżniania, czy na zdjęciu jest dorosły człowiek, czy małe dziecko, a może kot lub pies. Jednak obecnie badacze danych wiedzą, że te przekonania nie są już prawdą.
Dzięki technologii uczenia maszynowego uzyskaliśmy sukcesy w uczeniu komputerów wykonywania intuicyjnych zadań bez wyraźnego i dokładnego wyjaśniania zadań tym maszynom. Po prostu po zapisaniu w pamięci komputera dostatecznie dużej liczby różnych przykładów, takich jak np. zdjęcia psów i kotów, a następnie ich odpowiednich opisów, maszyna może nauczyć się określania obiektów na nowych zdjęciach za pomocą identyfikacji wzorców z przykładów. Podobnie do tego komputery potrafią obecnie dzięki technologii ML bez skomplikowanego kodowania rozwiązywać napotykane w przemyśle problemy, które wydawały się dawniej nie do rozwiązania.
Urządzenia pracujące w hali fabrycznej mogą teraz wysyłać ogromne ilości danych o procesach produkcyjnych, które są następnie przetwarzanie przez algorytmy ML komputerów. Na przykład w kontroli jakości procesu druku algorytm ML potrafi wykryć użycie nieprawidłowego koloru, niedokładne położenie, brakujące detale lub inne defekty. Komputer potrafi w miarę upływu czasu nauczyć się wykonywania testów pod kątem wspomnianych wad lub jeszcze innych i nie ma potrzeby, aby programista wstępnie zdefiniował wszystkie parametry testów kontroli jakości. Te analizowane szczegóły końcowego produktu drukowanego decydują, czy produkt ten przejdzie cały test kontroli jakości, czy też nie.
W miarę jak komputer staje się coraz bardziej zaznajomiony z procedurami produkcji, potrafi przetworzyć dane pochodzące z procesu produkcji na informacje, które mogą być wykorzystane w czasie niemal rzeczywistym do określenia, czy konkretna partia produkcyjna przejdzie testy kontroli jakości. Niejednokrotnie można dokonać poprawek parametrów procesu produkcji, aby ocalić partię wyrobów, która nie przejdzie testów. Poprzez identyfikację w zebranym zbiorze danych głównych czynników mających wpływ na jakość komputer potrafi, w odróżnieniu od człowieka, szybko zidentyfikować wzorce. Dzięki temu można automatycznie dokonać poprawek parametrów produkcji lub zaalarmować operatorów, którzy zrobią to ręcznie.
Wyzwania związane z uczeniem maszynowym
Niestety, wdrożenie technologii uczenia maszynowego nie jest prostym rozwiązaniem typu plug-and-play. Podobnie jak uczeń w szkole, maszyna wymaga prawidłowego poinstruowania, aby mogła perfekcyjnie wykonywać swoje zadania.
Zbieranie danych wysokiej jakości jest wielkim początkowym wyzwaniem w procesie wdrożenia ML. Etap ten jest kluczowy dla uzyskania sukcesu, ponieważ maszyna nie potrafi uczyć się na podstawie uszkodzonych, zakłóconych, zniekształconych lub niezakwalifikowanych danych. Prawidłowe zbieranie danych obejmuje ich zapis w standaryzowanym formacie, co czasami wymaga ich przetworzenia z oryginalnego „surowego” (ang. raw) formatu.
Po zakończeniu zbierania danych model sztucznej inteligencji wymaga dostarczenia zbioru danych oznaczonych (labeled data) do nauki. Ten zbiór danych jest dzielony na kategorie według klasy, takie jak OK lub nie OK, zakwalifikowane lub niezakwalifikowane, jednak wiele organizacji nie posiada specjalistów ani zasobów, dzięki którym mogłyby identyfikować i oznaczać te wzorce ML.
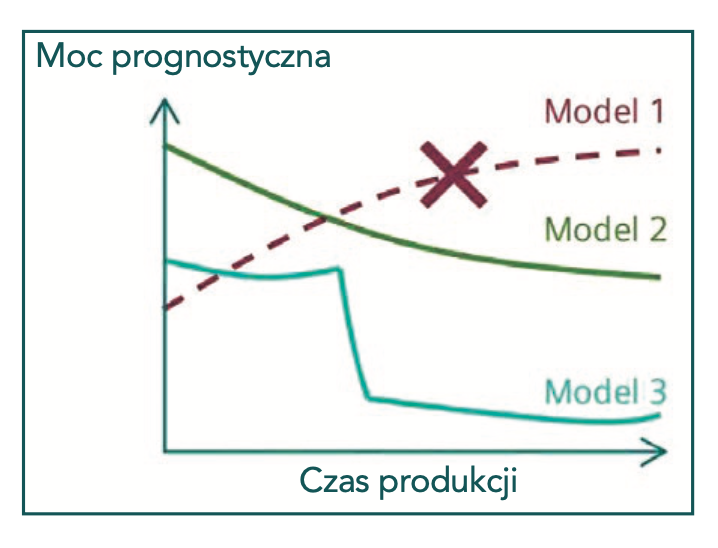
Modele sztucznej inteligencji często wykorzystują do treningu statyczne, historyczne ekstrakty z dynamicznych zazwyczaj danych. Jednak dane dotyczące produkcji przemysłowej mogą się gwałtownie zmieniać w nieznany i niewykryty sposób już po wdrożeniu modeli ML, a to z powodu zmiennych warunków procesów technologicznych, dynamicznych interwencji człowieka oraz innych przyczyn. To zwykle prowadzi do pogorszenia zdolności predykcyjnych oraz niezawodności modelu w miarę upływu czasu (patrz Rys. 1).
Gdy model źle klasyfikuje właściwości lub prezentuje wyniki o niskim poziomie wiarygodności, to konieczne jest ponowne wytrenowanie go za pomocą nowego lub dodatkowego zbioru danych oznaczonych.
Monitorowanie systemów produkcyjnych
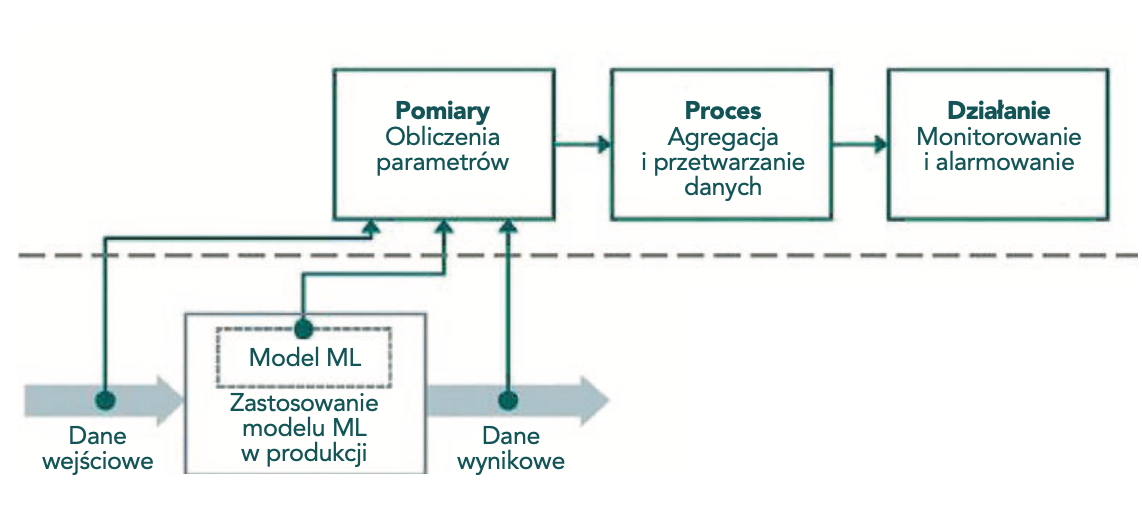
Typowa aplikacja ML odbiera dane z takich urządzeń jak kamery, mikrofony, czujniki temperatury oraz inne. Po imporcie i wstępnej obróbce danych model ML analizuje te dane i tworzy wyjście modelowe (patrz Rys. 2).
Przykład praktyczny – przewidywanie jakości produktu. Dane wyjściowe z modelu są często wynikiem odnoszącym się do jakości produktu albo prawdopodobieństwa wyprodukowania akceptowalnej lub wadliwej części czy partii. Aplikacja ML przesyła te prognozy jakości do różnych systemów w firmie, takich jak MES (system realizacji produkcji), który potrafi wtedy dostroić parametry technologiczne w celu optymalizacji jakości wyrobów lub po prostu wyświetlić odpowiednie informacje operatorowi.
Aby zapobiec pogarszaniu się dokładności modelu wraz z upływem czasu, aplikacja ML musi porównywać przewidywane dane wyjściowe z wynikami rzeczywistymi, dokonując w przyszłości dostrajania modelowania na podstawie odchyleń wartości prognozowanych od rzeczywistych.
Rozwiązanie uniwersalne
Gdy czujniki i inne urządzenia obiektowe wysyłają sygnały do komputerów i serwerów w zakładzie oraz w wielu przypadkach do chmury obliczeniowej, to pomagają w ten sposób w stworzeniu obrazu bieżącego stanu funkcjonowania fabryki. Informacje uzyskane na podstawie danych są wykorzystywane przez operatorów maszyn i urządzeń oraz kierownictwo do zwiększania wydajności produkcji, zapewniania bezpieczeństwa i dostosowywania się do nowych wymagań określonych przepisami czy standardami.
Technologia cyfrowych bliźniaków jak żadne inne narzędzie ułatwia proces stałej optymalizacji. Dane zebrane z czujników w hali fabrycznej potrafią znacznie zwiększyć efektywność operacji realizowanych w zakładzie.
Ten typ narzędzia nie tylko ujawnia zdefiniowany produkt wytworzony z konkretnych materiałów czy składników, posiadający znaną masę, wyprodukowany określonego dnia i mający konkretną jakość. Może też jednak ujawnić takie dane, jak temperatura, wilgotność i wiele innych, które mają wpływ na produkt końcowy, a następnie skorelować te czynniki środowiskowe z jakością produktu końcowego. Ten kompletny zbiór danych umożliwia stworzenie cyfrowego bliźniaka procesu produkcji i samego produktu, co jest kompletną wirtualną prezentacją produktu i sposobu jego wytworzenia.
W przypadkach, w których trudno jest wygenerować dane rzeczywiste do wytrenowania modelu, specjalista może stworzyć cyfrowego bliźniaka, uruchamiając symulacje w celu stworzenia zbioru niezbędnych danych o produkcie, aby wytrenować model ML. Cyfrowe bliźniaki umożliwiają lepsze i szybsze opracowanie produktu, ponieważ technologia symulacji przyśpiesza projektowanie i testowanie na długo zanim zostaną wytworzone prototypy fizyczne. Cyfrowe bliźniaki zwiększają też efektywność projektowania, ponieważ umożliwiają deweloperom wypróbowanie i porównanie większej liczby konfiguracji, niż jest to możliwe w przypadku modeli fizycznych (patrz Rys. 3).
Na przykład cyfrowy bliźniak może być wykorzystany do zwiększenia efektywności energetycznej nowego budynku jeszcze przed rozpoczęciem prac budowlanych. Poza włączeniem wizualizacji elementów geometrycznych tego budynku cyfrowy bliźniak może zawierać harmonogram i budżet realizacji projektu oraz dane dotyczące dostaw energii do budynku, oświetlenia, instalacji przeciwpożarowej, a także dane operacyjne. W wyniki tego inżynierowie mogą zoptymalizować wpływ klimatyczny przyszłego budynku jeszcze przed rozpoczęciem wykopów pod fundamenty.
Ponadto cyfrowy bliźniak zbiera dane w ciągu całego swojego cyklu życia. Dane te mogą obejmować obciążenia fizyczne, komponenty, które uległy awarii lub funkcjonowanie obiektów, takie jak np. frezarka, samolot czy budynek. Takie informacje wspierają optymalizację podczas operacji oraz pomagają projektantom, architektom oraz inżynierom w przygotowaniu nowych generacji produktów.
Nauczenie się „metody mrówek”
Aby tworzyć dokładne cyfrowe bliźniaki rzeczywistych systemów technicznych, deweloperzy muszą rozumieć wartości materialne systemu, dane projektowe, funkcjonalne przepływy robocze oraz otaczające prawa natury. Cyfrowy bliźniak musi także rejestrować rozbieżności pomiędzy systemowymi wartościami modelowanymi a rzeczywistymi, aby utrzymywać dokładność w czasie.
Wykorzystując technologię uczenia maszynowego oraz właściwe komputerom szybkie przetwarzanie dużych zbiorów danych, model może ujawniać bardzo złożone powiązania, których człowiek nie mógłby wyznaczyć. Komputer może wykorzystać „metodę mrówek” do efektywnej optymalizacji modelu.
W przyrodzie kolonie mrówek wykorzystują substancje zapachowe do znaczenia swoich ścieżek podczas poszukiwania pokarmu. Ponieważ mrówki częściej wykorzystują najkrótszą ścieżkę, częstsze znakowanie jej zamiast ścieżek dłuższych powoduje, że w miarę upływu czasu wydziela ona coraz silniejszy zapach.
Podobnie jak mrówki do znaczenia swoich ścieżek, modelowanie oparte na ML wykorzystuje tę metodę do optymalizacji procesów produkcyjnych w miarę upływu czasu, ponieważ symulowanie wszystkich możliwych do opracowania procedur i porównywanie ich ze sobą nawzajem jednocześnie wyczerpałoby zasoby obliczeniowe komputera. Zamiast tego komputer zmienia procedurę produkcji kawałek po kawałku w miarę jak tworzy korelacje pomiędzy metodami operacyjnymi a wynikami testów kontroli jakości. Ta metodologia umożliwia modelowi ML wyznaczenie najbardziej efektywnej drogi realizowania operacji.
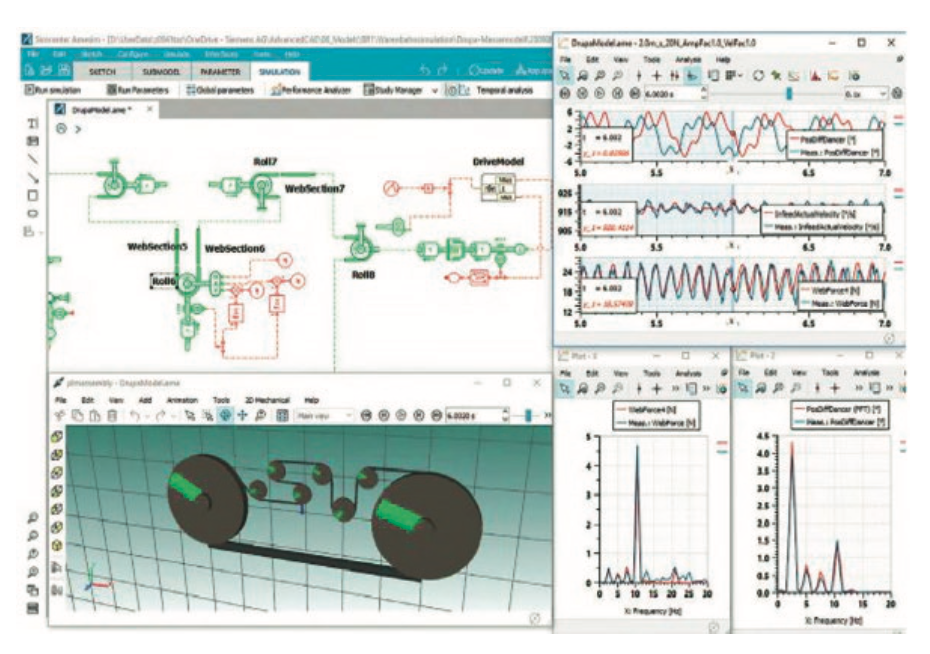
Pewien czołowy producent układów przeniesienia napędu do pojazdów z silnikami benzynowymi, Diesla oraz elektrycznymi zaczął wykorzystywać oprogramowanie SimCenter Amesim firmy Siemens do opracowania i sprzężenia wirtualnych czujników ze sztuczną inteligencją. To oprogramowanie do symulacji układów mechatronicznych umożliwiło firmie przemysłowej stworzenie wirtualnych modeli (patrz Rys. 4) swoich układów przeniesienia napędu w celu określenia idealnych parametrów konstrukcyjnych przed wyprodukowaniem fizycznych prototypów, co pozwoliło firmie na uniknięcie zmarnowania czasu i środków na ewentualne wadliwe prototypy.
Poza projektowaniem sprzętu producent wykorzystał model wirtualny do optymalizacji strategii sterowania działaniem swoich wyrobów. Przekładając ten model na format nadający się do wdrożenia we wbudowanych w napędy elektronicznych układach sterowania, specjaliści z firmy wyposażyli te sterowniki w możliwości uczenia maszynowego, oparte na technologii sztucznej inteligencji. To dało układom przeniesienia napędu możliwość automatycznej adaptacji wyjściowej prędkości i momentu obrotowego do bieżącego cyklu jazdy oraz aplikacji pojazdu.
Wykorzystanie rozpoznawania wzorców przez komputery
W miarę upływu czasu, wykorzystując zbiory prawidłowo oznaczonych danych, algorytmy ML działają coraz lepiej, a cyfrowe bliźniaki stają się standardem w projektowaniu produktów, fabryk oraz systemów automatyki. W rezultacie te technologie są coraz częściej akceptowane przy certyfikacjach, takich jak zgodność z przepisami bezpieczeństwa oraz ochrony środowiska.
Ponieważ cyfrowe bliźniaki stają się coraz popularniejsze, będą one łączone z dostarczaniem na rynek systemów i produktów fizycznych, umożliwiając użytkownikom tej technologii stawianie hipotez oraz testowanie wyników modyfikacji swoich projektów i procesów przed uruchomieniem produkcji.
Dzięki wnikliwej technologii uczenia maszynowego i rozpoznawaniu wzorców dane z symulacji wykonywanych przez cyfrowe bliźniaki oraz dane rzeczywiste z czujników obiektowych mogą być przetwarzane w celu tworzenia dokładnych i sprawdzonych w czasie modeli produkcyjnych. Modele te przyśpieszają optymalizację procesów i maszyn przemysłowych, zwiększając wydajność produkcji oraz skracając czas wprowadzania produktów na rynek, jednocześnie redukując koszty utrzymania ruchu oraz przestoje.
Alessandra Da Silva, menedżer ds. marketingu produktu w firmie Siemens Industry Inc.


