



Proces przygotowywania surowych danych, uzyskiwanych z czujników w zakładach przemysłowych, do analizy w celu uzyskania użytecznych dla firmy informacji, jest bardzo ważny i jak mówi stare porzekadło, „diabeł tkwi w szczegółach”.
Obecnie ma miejsce wysyp dobrze opisanych i powszechnie wykorzystywanych systemów tworzenia i przechowywania danych szeregów czasowych, w tym programów do archiwizacji danych, oprogramowania typu open source czy jezioro danych (data lake) oraz usług w chmurze obliczeniowej. Ze względu na te atrakcyjne opcje przechowywania danych oraz niższe ceny czujników i systemów zbierania danych, organizacje przemysłowe masowo wdrażają technologię Przemysłowego Internetu Rzeczy (IIoT) i analitykę Big Data. Ale na co najczęściej uskarżają się te firmy? Na to, że są jednocześnie bogate w dane i ubogie w informacje. Wielka ilość zbieranych obecnie w zakładach przemysłowych danych przekłada się, niestety, na bardzo małą ilość użytecznych, dających się wykorzystać w praktyce informacji (insights).
Jednym z głównych problemów tych firm przemysłowych jest to, że zebrane dane nie są gotowe do analizy i uzyskania z nich korzyści, co jest głównym celem ich zbierania i przetwarzania. Według niektórych szacunków ponad 70% wysiłku włożonego w analizę wykorzystuje się obecnie do prostego przenoszenia danych ze stanu „surowego do gotowego”. Wykonuje się to za pomocą czyszczenia danych (data cleansing) lub, jak nazywa to New York Times, pracy „sprzątacza danych” (data janitor). Ta nieustanna monotonia zbierania, organizowania, czyszczenia i kontekstualizowania danych w procesie analitycznym jest zatem ogromną przeszkodą dla tworzenia wartości z surowych danych.
Dostęp do danych
Aby przekształcić dane z „surowych do gotowych” i dopasowanych do analizy, muszą zostać spełnione dwa warunki: posiadanie dostępu do danych oraz wiedzy fachowej – przez pracowników zakładów.
Błędem jest przyjmowanie, że większość pracowników w przemyśle ma łatwy dostęp do danych. W wielu organizacjach użytkownicy mają zablokowany dostęp do danych, których potrzebują do analizy. Dzieje się tak, ponieważ zarządzanie danymi – zasady i procesy, których muszą przestrzegać pracownicy, aby uzyskać dostęp do danych – jest przedmiotem zainteresowania wielu działów IT, które próbują rozwiązywać problemy związane z bezpieczeństwem, prywatnością i poufnością danych.
Jednocześnie dostęp do danych jest warunkiem wstępnym tego, co będzie się działo dalej, czyli procesu tworzenia danych gotowych do analizy, mającej na celu uzyskanie z nich praktycznych, użytecznych dla firmy informacji. Ponadto wyraźnie najlepszą praktyką dla organizacji produkcyjnych jest przechowywanie danych procesowych w ich natywnej formie, bez ich podsumowywania lub czyszczenia. Dzieje się tak, ponieważ wszelkie założenia na temat sposobu manipulowania danymi przed ich analizą mogą mieć negatywny wpływ na badanie danych (data investigation).
Manipulacja danymi powinna być wykonywana tylko w czasie analizy, a następnie tylko przez eksperta dziedzinowego (subject matter expert – SME), kierującego pracami związanymi z analizą danych. Podążanie drogą czyszczenia danych, podsumowywania danych lub innych zmian w danych źródłowych stwarza zatem ryzyko usunięcia dokładnie tych danych i szczegółów, które mogłyby okazać się ważne dla badania danych. Tak więc dostęp do danych w ich formie źródłowej jest pierwszym warunkiem wstępnym poprawnego przygotowania danych do analizy.
Wiedza fachowa pracowników zakładów
Drugim warunkiem poprawnego przygotowania danych do analizy jest wiedza fachowa ekspertów dziedzinowych, inżynierów procesu oraz innych pracowników, znających dane, zasoby i procesy swojej fabryki lub zakładu. Tacy eksperci już od 30 lat analizują dane za pomocą arkuszy kalkulacyjnych, a przedtem wykonywali to za pomocą suwaków logarytmicznych, długopisów i kartek papieru.
Połączenie tych pracowników i ich wiedzy z dostępem do danych jest kluczowym krokiem, ponieważ tylko w czasie analizy można podjąć właściwe decyzje w odniesieniu do kolejnych etapów czyszczenia i kontekstualizacji danych. Bez tej wiedzy wynik analizy jest często niewłaściwy – podający błędne korelacje lub znane już zależności, które są rozumiane w kontekście całej fabryki, jeśli nie przez osoby skoncentrowane jedynie na informatyce. Innymi słowy, algorytm analityki Big Data zazwyczaj ujawnia tysiące potencjalnych problemów, z których niewiele jest prawdziwymi wyzwaniami. Na przykład: kto w firmie potrzebuje uzyskać z analizy danych rewelacje typu: żaden produkt nie jest wytwarzany, gdy następuje odcięcie dostawy energii elektrycznej do fabryki?
Wprowadzając do akcji tę pierwszą linię ekspertów w swoich organizacjach, producenci mogą dzięki analizie danych osiągnąć szereg korzyści: zwiększenie wydajności produkcji, dyspozycyjności sprzętu, produktywności oraz zysku.
Mając dostęp do danych, eksperci dziedzinowi mogą przygotować dane do analizy poprzez integrację i zestawienie danych pochodzących z różnych źródeł, co nazywane jest też kontekstualizacją. Kontekstualizacja obejmuje wiele terminów, w zależności od producenta i gałęzi przemysłu – w tym harmonizację danych (data harmonization), mieszanie danych (data blending), łączenie danych (data fusion) oraz generowanie sztucznych danych (data augmentation) – które oznaczają to samo: integrację danych z zamiarem uzyskania informacji lub integrację różnych typów danych. Trudność polega na tym, że w sygnale szeregów czasowych brak jest „uchwytów”, tak więc eksperci muszą (podczas analizy) znaleźć sposób na zintegrowanie odpowiedzi na następujące pytania: „Co teraz mierzę” (dane z czujnika) z „Co teraz robię” (co w danym momencie wykonuje zasób lub proces), a nawet „Jaka część danych jest dla mnie ważna?”
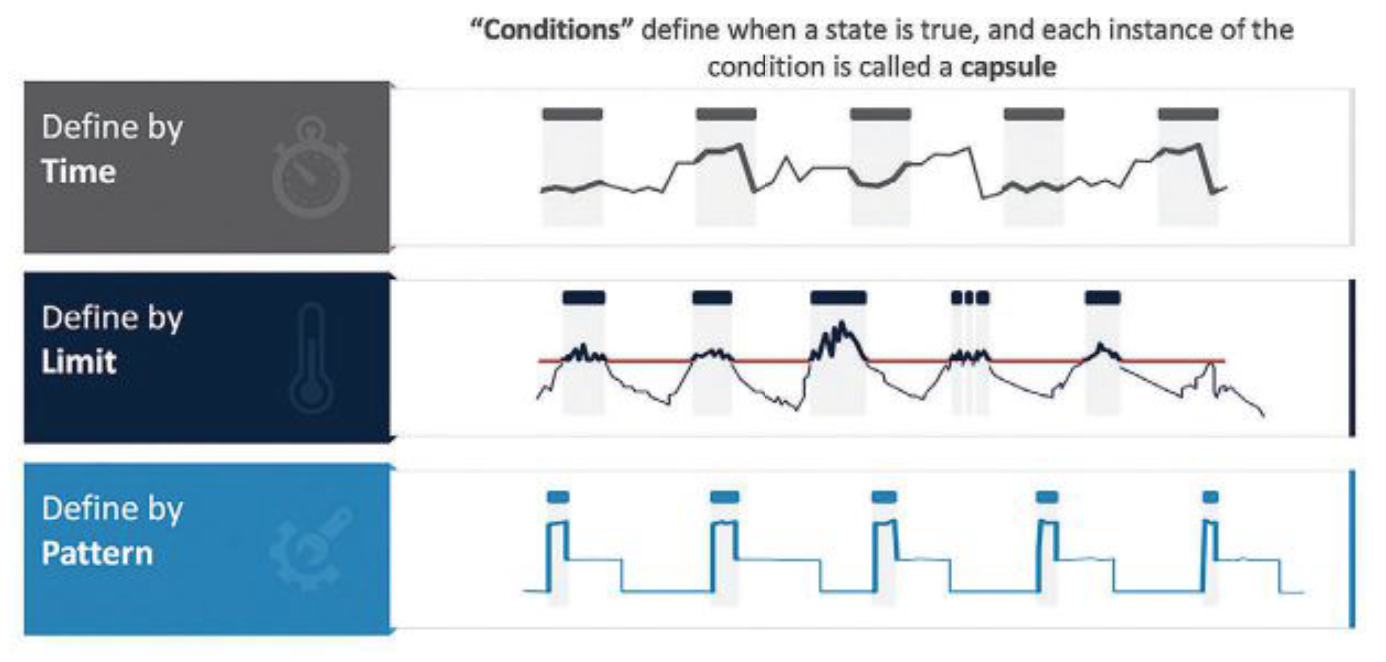
Tworzenie kontekstu
Jako przykład wyzwań napotykanych podczas pracy z danymi szeregów czasowych rozważmy prosty zbiór danych szeregów czasowych z danymi z czujnika, rejestrowanymi co sekundę przez rok, aby utworzyć w efekcie 3,1 miliona punktów danych, każdy w formacie: znacznik czasu:wartość.
Najprawdopodobniej użytkownik nie będzie chciał wykorzystać wszystkich danych sygnałowych do analizy; zamiast tego będzie chciał tylko zidentyfikować interesujące go okresy w sygnale. Na przykład być może użytkownik potrzebuje „uchwytów” dla okresów czasu w danych do analizy, zdefiniowanej przez:
- przedział czasowy: dzień, zmiana robocza, wtorki, dni powszednie w porównaniu do weekendów itp.,
- stan zasobu: włączony, wyłączony, rozgrzewanie, wyłączanie itp.,
- obliczanie: okresy, w których druga pochodna średniej ruchomej jest ujemna,
- próbki danych, które są błędami: utracone sygnały, chwilowe zaniki sygnału lub inne problemy, które wymagają oczyszczenia danych, w celu poprawy dokładności analizy.
Innymi słowy, interesujące eksperta okresy czasu to takie, w których zdefiniowany warunek jest prawdziwy, a resztę danych można zignorować dla celów analizy. Interesujące okresy czasu można wybrać do wykorzystania jako punkty integracji z relacyjnymi lub dyskretnymi typami danych (rys. 1).
Dodajmy do tego przykładu dwa komentarze. Po pierwsze, nawet w przypadku prostego przykładu danych jednego sygnału, zebranych w ciągu jednego roku, oczywiste jest, że istnieje nieskończona liczba sposobów, w jaki sygnał ten może być dzielony lub wykorzystany do celów analitycznych. Ponieważ istnieje tak wiele możliwych opcji, wybór interesujących okresów powinien odbywać się w „czasie analizy”, kiedy intencja użytkownika jest jasna i można zidentyfikować odpowiednie segmenty czasowe. Ponadto ten przykład to tylko jeden sygnał. Wyobraźmy sobie teraz środowiska produkcyjne z liczbą od 20 000 do 70 000 sygnałów, takie jak duże zakłady chemiczne, rafinerie ropy naftowej z liczbą 100 000 sygnałów lub korporacyjne zbiorcze dane z czujników, zawierające miliony sygnałów.
Kontekstualizacja w czasie analizy i wykonywana przez eksperta dziedzinowego jest tym, co transformuje dane szeregów czasowych – z falistej linii na wykresie kontrolnym – na będące przedmiotem zainteresowania obiekty danych do analizy, a wszystkie jej formy powinny być zawarte w jej definicji (rys. 2).
Po drugie, ważne jest, aby pamiętać, że każda analiza danych szeregów czasowych obejmuje próbkowanie danych sygnałowych przy ścisłym przestrzeganiu wyzwań związanych z interpolacją i rachunkiem różniczkowym, czego zwykle nie obejmują prace związane z konsolidacją/agregacją danych IT. Dlatego wymagane jest użycie do kontekstualizacji rozwiązań specyficznych dla produkcji w danym zakładzie. Możliwość wyrównania sygnałów o różnych częstotliwościach próbkowania, pochodzących z różnych źródeł, w różnych strefach czasowych, obejmujących czas letni lub inne zmiany, jest absolutnym wymogiem przed wprowadzeniem definicji odpowiednich okresów czasu.
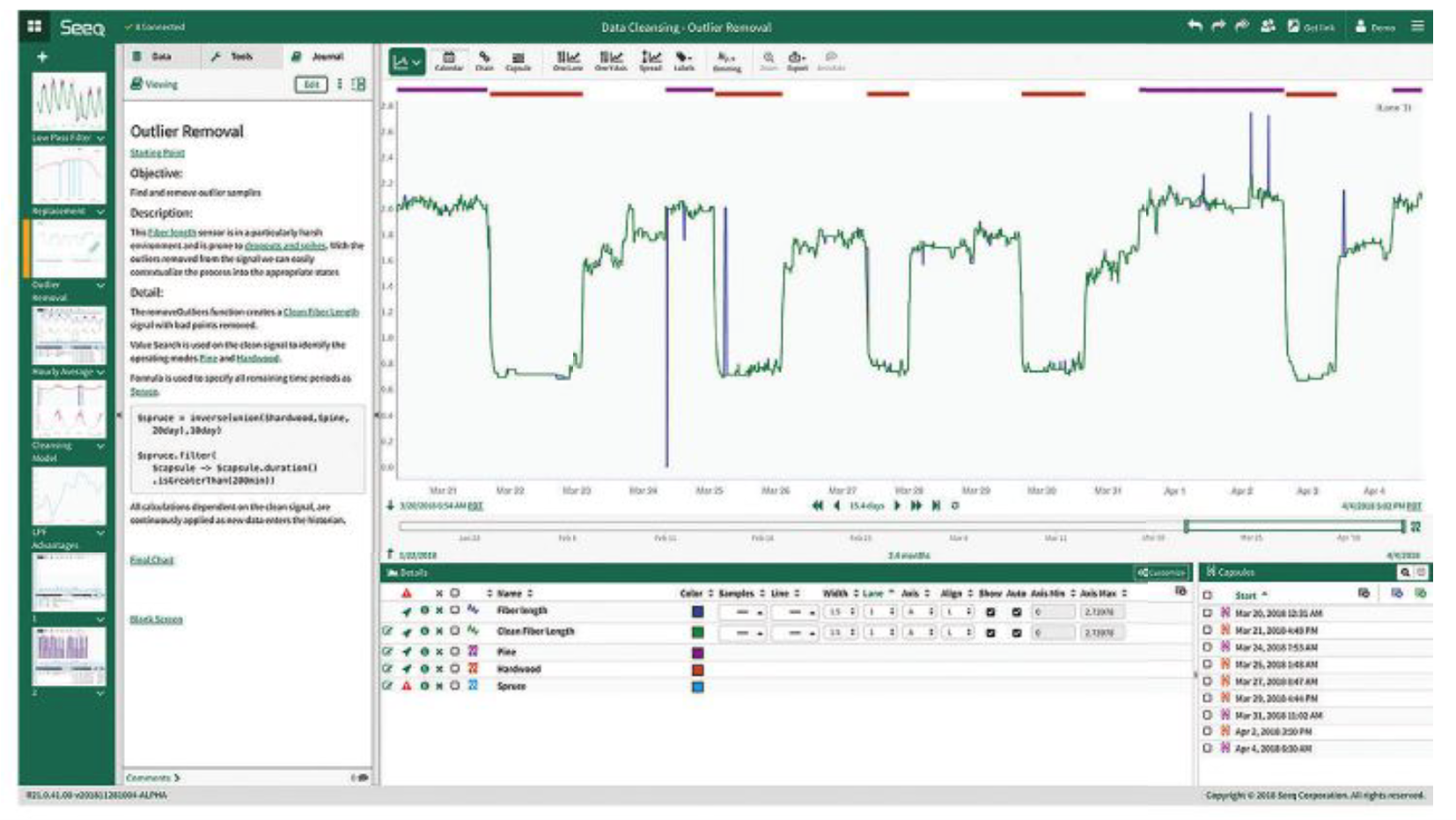
Ostatni etap kontekstualizacji
Ostatnim etapem kontekstualizacji, po zidentyfikowaniu interesujących okresów w sygnałach szeregów czasowych, jest dalsza kontekstualizacja danych z innych źródeł. Ma to na celu uzyskanie praktycznych i użytecznych informacji, obejmujących produkcję i wyniki biznesowe firmy przemysłowej. Pytania, jakie mogą zadawać organizacje, które wymagają wykorzystywania wielu różnorodnych zbiorów danych, mogą być np. takie:
- Jakie jest zużycie energii podczas wytwarzania produktu typu 1 w porównaniu z produktem typu 2?
- Jaki jest wpływ temperatury na jakość produktu?
- Czy zużycie energii zmienia się wraz ze zmianą czasu realizacji partii produkcyjnej?
Źródłami danych mogą być: laboratoryjne systemy informatyczne, systemy realizacji produkcji (MES), systemy planowania zasobów przedsiębiorstwa (ERP), zewnętrzne systemy wyceny surowców oraz inne.
W poniższym przykładzie przedstawiono przypadek kontekstualizacji dla danych szeregów czasowych, a następnie dla danych z innych źródeł. Wynikiem tej kontekstualizacji jest tabela, która jest łatwa do zrozumienia i manipulowania, dostępna dla ekspertów dziedzinowych i każdego analityka, korzystającego z aplikacji do analizy biznesowej, takiej jak Microsoft Power BI, Tableau lub Spotfire (rys. 3).
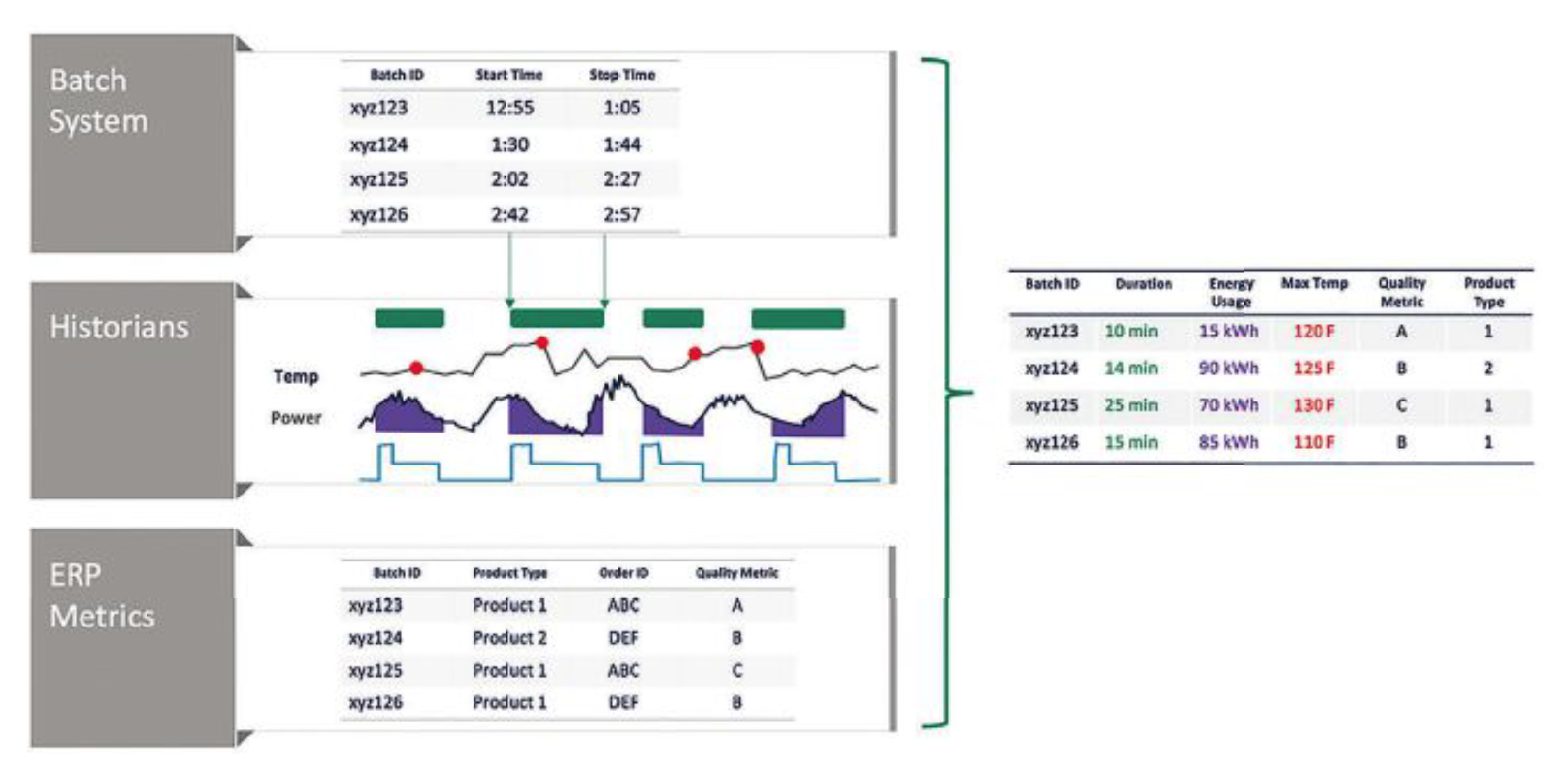
Perspektywy na przyszłość
Obecnie zwraca się coraz więcej uwagi i wywiera coraz więcej nacisków na organizacje przemysłowe, aby przeprowadzały transformację cyfrową wraz z wymaganą integracją technologii informatycznej z technologią operacyjną (IT/OT), niezbędną dla dostarczenia zintegrowanego obrazu firmy na podstawie zbiorów danych biznesowych i produkcyjnych. A zatem dla organizacji produkcyjnych coraz ważniejsze staje się uznanie znaczenia kontekstualizacji, niezależnie od wybranej strategii przechowywania swoich danych szeregów czasowych.
Eksperci dziedzinowi muszą wykonywać kontekstualizację, aby przygotowywać dane do analizy. Tylko eksperci dziedzinowi posiadają odpowiednią wiedzę i rozumieją potrzeby wykonywania analiz danych, dzięki czemu będą wiedzieli, czego właściwie szukają w czasie wykonywania tych analiz. Obejmuje to możliwość bardzo szybkiego definiowania, składania i pracy z interesującymi okresami w danych szeregów czasowych, w tym dostęp do powiązanych danych w systemach produkcyjnych, biznesowych, laboratoryjnych oraz innych.
Dlatego organizacje przemysłowe, które dostosują wymagania kontekstualizacji analizy danych szeregów czasowych do swojej strategii danych, będą miały większą szansę na poprawę wyników produkcji poprzez wykorzystanie praktycznych informacji, uzyskanych na podstawie analizy danych.
Michael Risse jest dyrektorem ds. marketingu (CMO) i wiceprezesem w firmie Seeq Corporation. Firma ta tworzy zaawansowane aplikacje analityczne dla inżynierów i analityków danych, które przyspieszają uzyskiwanie praktycznych informacji na temat procesów przemysłowych. Michael Risse wcześniej był konsultantem w firmach zajmujących się platformami i aplikacjami Big Data, a przedtem jeszcze przez 20 lat współpracował z firmą Microsoft. Jest on absolwentem Uniwersytetu Wisconsin w Madison, obecnie mieszka w Seattle.


